Focus
Modular, secure, and scalable architecture
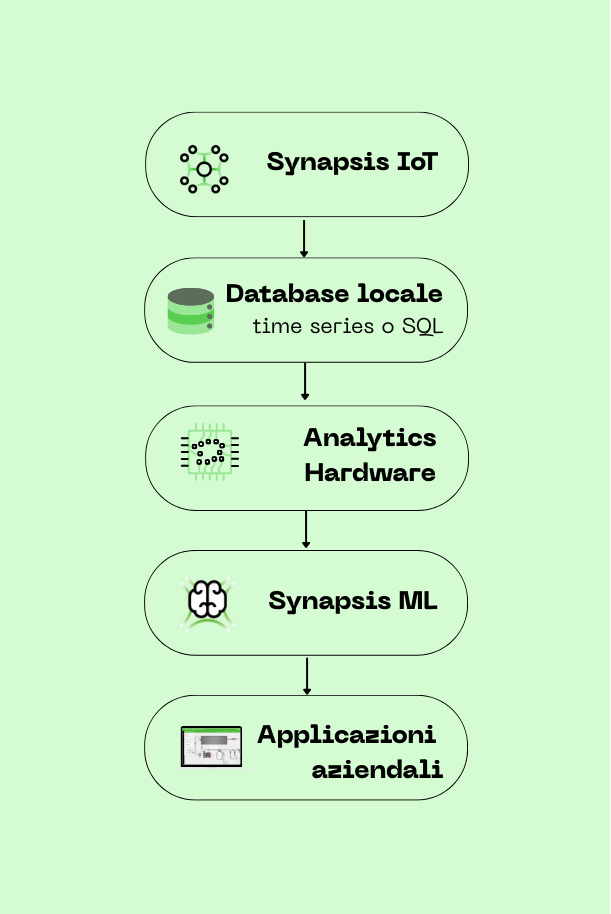
The architecture of Synapsis ML is designed to offer a local, modular, and scalable AI solution, composed of three fundamental elements that interact synergistically:
1. Company Data Sources
The platform integrates directly with the company's internal databases (SQL and time series), where data from IoT systems and field sensors is recorded. This integration occurs via secure APIs, without data export or duplication, fully preserving the client's IT environment.
2. Dedicated AI Hardware
The computational core of the system is a hardware module installed on the client’s site. This edge device is optimized to perform complex AI calculations (inference and training) with low latency and high energy efficiency. It allows model execution directly within the company perimeter, reducing response times and increasing operational resilience.
Examples of employed hardware:
- NVIDIA Jetson Nano
- ASTRIAL-HAILO 10
3. Synapsis ML Intelligent API
The API is the single access point to the entire platform and coordinates the two AI components:
- AI ML: Custom-trained by the Mative team to generate forecasts, detect anomalies, or classify operational states, with structured and measurable outputs.
- AI LLM: Ready-to-use, it applies RAG (Retrieval-Augmented Generation) to access internal textual company content (manuals, reports, technical documentation) and respond in natural language, transforming complex texts into usable answers.
This distributed and local architecture enables Synapsis ML to operate even in environments with strict security requirements, ensuring real-time data processing and full integration with existing corporate systems. The system’s modularity also allows for expanding processing capacity or integrating new data sources without modifying the existing infrastructure.